The GitHub repository for TidyTuesday was cloned from https://github.com/rfordatascience/tidytuesday, and the CSV files for 4/11/2023 were copied and pasted into the data folder of this portfolio.
Load Libraries
# Data Handlinglibrary(tidyverse)
Warning: package 'tidyverse' was built under R version 4.2.3
Warning: package 'ggplot2' was built under R version 4.2.3
Warning: package 'tibble' was built under R version 4.2.3
Warning: package 'tidyr' was built under R version 4.2.3
Warning: package 'readr' was built under R version 4.2.3
Warning: package 'dplyr' was built under R version 4.2.3
Warning: package 'forcats' was built under R version 4.2.3
Warning: package 'lubridate' was built under R version 4.2.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.1 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.1 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
## Information About NAslibrary(dlookr)
Attaching package: 'dlookr'
The following object is masked from 'package:tidyr':
extract
The following object is masked from 'package:base':
transform
Warning: package 'broom' was built under R version 4.2.3
Warning: package 'modeldata' was built under R version 4.2.3
Warning: package 'parsnip' was built under R version 4.2.3
Warning: package 'recipes' was built under R version 4.2.3
Warning: package 'workflows' was built under R version 4.2.3
── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
✖ scales::discard() masks purrr::discard()
✖ dlookr::extract() masks tidyr::extract()
✖ dplyr::filter() masks stats::filter()
✖ recipes::fixed() masks stringr::fixed()
✖ dplyr::lag() masks stats::lag()
✖ yardstick::spec() masks readr::spec()
✖ recipes::step() masks stats::step()
• Learn how to get started at https://www.tidymodels.org/start/
library(rpart)
Attaching package: 'rpart'
The following object is masked from 'package:dials':
prune
Load Data
# First Datasetcage_free_data <-read_csv("data/cage-free-percentages.csv")
Rows: 96 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): source
dbl (2): percent_hens, percent_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Second Datasetegg_production_data <-read_csv("data/egg-production.csv")
Rows: 220 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): prod_type, prod_process, source
dbl (2): n_hens, n_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Explore Data
# Cage-Free Eggsstr(cage_free_data)
spc_tbl_ [96 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ observed_month: Date[1:96], format: "2007-12-31" "2008-12-31" ...
$ percent_hens : num [1:96] 3.2 3.5 3.6 4.4 5.4 6 5.9 5.7 8.6 9.9 ...
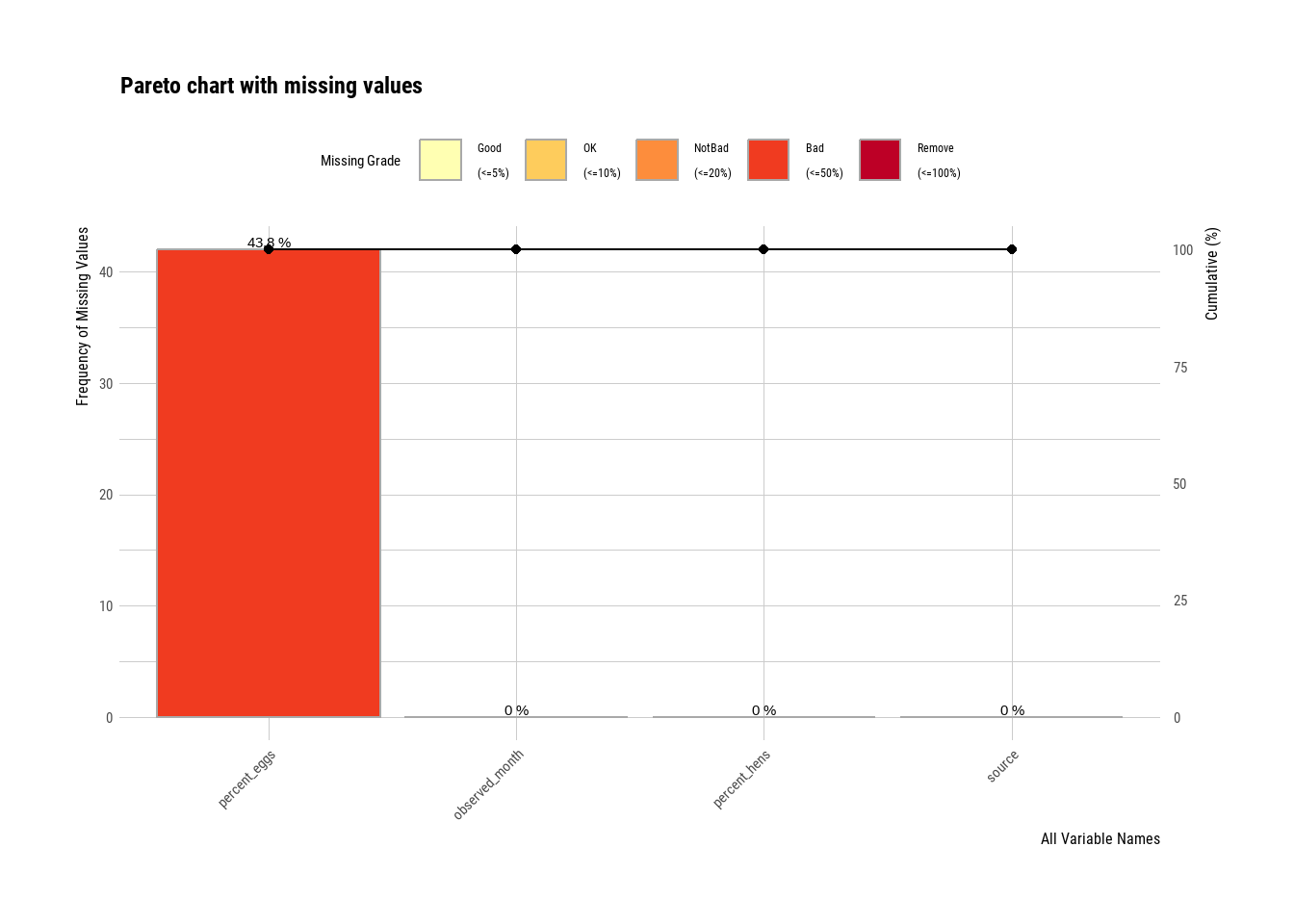
$ percent_eggs : num [1:96] NA NA NA NA NA NA NA NA NA NA ...
$ source : chr [1:96] "Egg-Markets-Overview-2019-10-19.pdf" "Egg-Markets-Overview-2019-10-19.pdf" "Egg-Markets-Overview-2019-10-19.pdf" "Egg-Markets-Overview-2019-10-19.pdf" ...
- attr(*, "spec")=
.. cols(
.. observed_month = col_date(format = ""),
.. percent_hens = col_double(),
.. percent_eggs = col_double(),
.. source = col_character()
.. )
- attr(*, "problems")=<externalptr>
summary(cage_free_data)
observed_month percent_hens percent_eggs source
Min. :2007-12-31 Min. : 3.20 Min. : 9.557 Length:96
1st Qu.:2017-05-23 1st Qu.:13.46 1st Qu.:14.521 Class :character
Median :2018-11-15 Median :17.30 Median :16.235 Mode :character
Mean :2018-05-12 Mean :17.95 Mean :17.095
3rd Qu.:2020-02-28 3rd Qu.:23.46 3rd Qu.:19.460
Max. :2021-02-28 Max. :29.20 Max. :24.546
NA's :42
head(cage_free_data)
# A tibble: 6 × 4
observed_month percent_hens percent_eggs source
<date> <dbl> <dbl> <chr>
1 2007-12-31 3.2 NA Egg-Markets-Overview-2019-10-19.pdf
2 2008-12-31 3.5 NA Egg-Markets-Overview-2019-10-19.pdf
3 2009-12-31 3.6 NA Egg-Markets-Overview-2019-10-19.pdf
4 2010-12-31 4.4 NA Egg-Markets-Overview-2019-10-19.pdf
5 2011-12-31 5.4 NA Egg-Markets-Overview-2019-10-19.pdf
6 2012-12-31 6 NA Egg-Markets-Overview-2019-10-19.pdf
observed_month prod_type prod_process n_hens
Min. :2016-07-31 Length:220 Length:220 Min. : 13500000
1st Qu.:2017-09-30 Class :character Class :character 1st Qu.: 17284500
Median :2018-11-15 Mode :character Mode :character Median : 59939500
Mean :2018-11-14 Mean :110839873
3rd Qu.:2019-12-31 3rd Qu.:125539250
Max. :2021-02-28 Max. :341166000
n_eggs source
Min. :2.981e+08 Length:220
1st Qu.:4.240e+08 Class :character
Median :1.155e+09 Mode :character
Mean :2.607e+09
3rd Qu.:2.963e+09
Max. :8.601e+09
head(egg_production_data)
# A tibble: 6 × 6
observed_month prod_type prod_process n_hens n_eggs source
<date> <chr> <chr> <dbl> <dbl> <chr>
1 2016-07-31 hatching eggs all 57975000 1147000000 ChicEggs-09-23-…
2 2016-08-31 hatching eggs all 57595000 1142700000 ChicEggs-10-21-…
3 2016-09-30 hatching eggs all 57161000 1093300000 ChicEggs-11-22-…
4 2016-10-31 hatching eggs all 56857000 1126700000 ChicEggs-12-23-…
5 2016-11-30 hatching eggs all 57116000 1096600000 ChicEggs-01-24-…
6 2016-12-31 hatching eggs all 57750000 1132900000 ChicEggs-02-28-…
# plot_na_pareto(egg_production_data) <-- Was edited out since no NA values were found for this dataset.
Question(s) and Hypothesis
Upon reviewing the datasets, two questions have come to mind:
Is there a month in which more eggs are produced than others?
Have the percentages of cage-free hens and eggs increased over time?
The hypotheses are therefore:
August sees the greatest production of eggs in general.
The percentages of cage-free hens and eggs have increased through the years.
Data Cleaning, Manipulation, and Processing
The data given by TidyTuesday appears mostly clean already, though it would probably be better to combine the two datasets into one during data cleaning/manipulation. According to the README, the cage-free data refers to what percent of hens and eggs out of all the production facilities in the United States are cage-free. It is therefore likely that the information in cage_free_data is already contained in egg_production_data in some way.
The two datasets also begin at different points in time, so we will choose the dataset that starts more recently (aka egg_production_data). Furthermore, since observed month comes in sets of 2, that makes it relatively easy to calculate total number of hens and eggs for each month indicated.
# Have Columns to Refer Back to Previous/Next Entriescompatible_egg_production_data <- egg_production_data %>%arrange(observed_month) %>%mutate(previous_n_hens =lag(n_hens, n =1)) %>%mutate(previous_n_eggs =lag(n_eggs, n =1)) %>%mutate(proximo_n_hens =lead(n_hens, n =1)) %>%mutate(proximo_n_eggs =lead(n_eggs, n =1))# Calculate Total Number of Hens and Eggs Based on Row Divisibility (Each Month Appears Twice)row_EO <-NAfor (row in1:nrow(compatible_egg_production_data)) { row_EO <-c(row_EO, row)}row_EO <- row_EO[2:221]compatible_egg_production_data$row_EO <- row_EOcompatible_egg_production_data <- compatible_egg_production_data %>%mutate(total_n_hens =case_when( row_EO %%2==0~ n_hens + previous_n_hens,TRUE~ n_hens + proximo_n_hens)) %>%mutate(total_n_eggs =case_when( row_EO %%2==0~ n_eggs + previous_n_eggs,TRUE~ n_eggs + proximo_n_eggs))
Data Visualization
Production of Eggs by Month
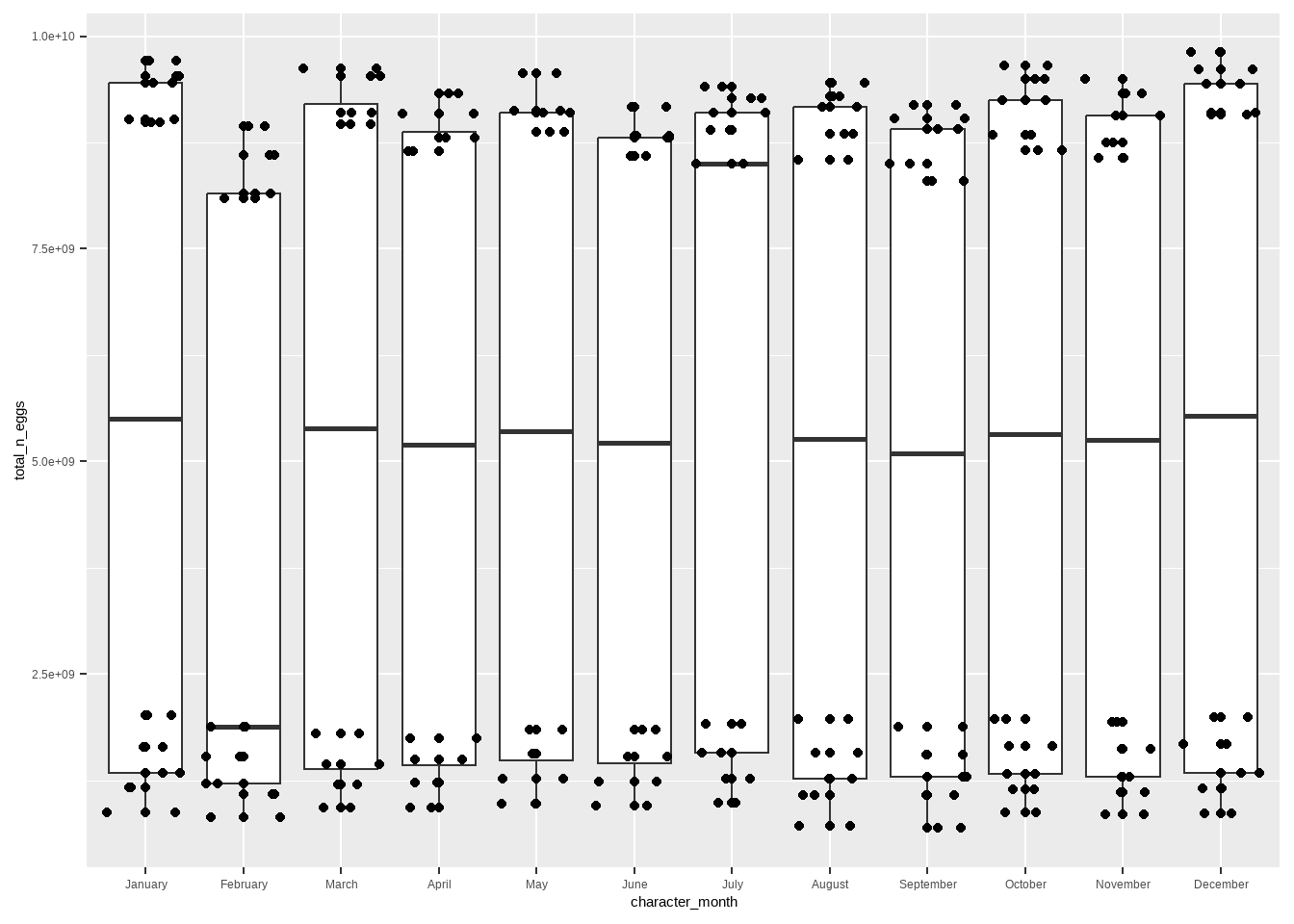
ggplot(compatible_egg_production_data, aes(x = character_month, y = total_n_eggs)) +geom_boxplot() +geom_point() +geom_jitter()
It appears that August is not when the most eggs are produced; rather, most eggs are produced in January and December, though it is noteworthy that July has a very high median of egg production in comparison to other months.
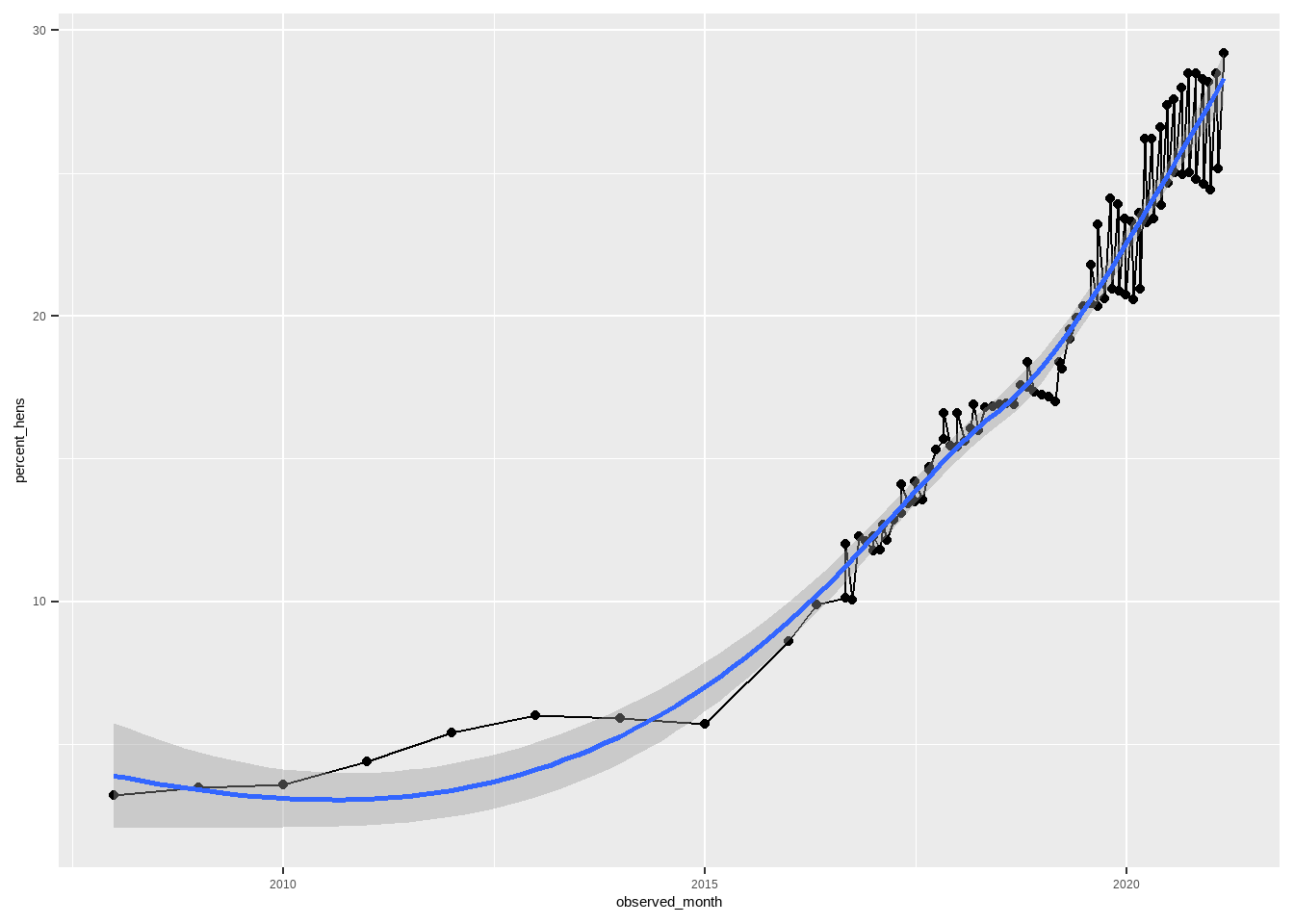
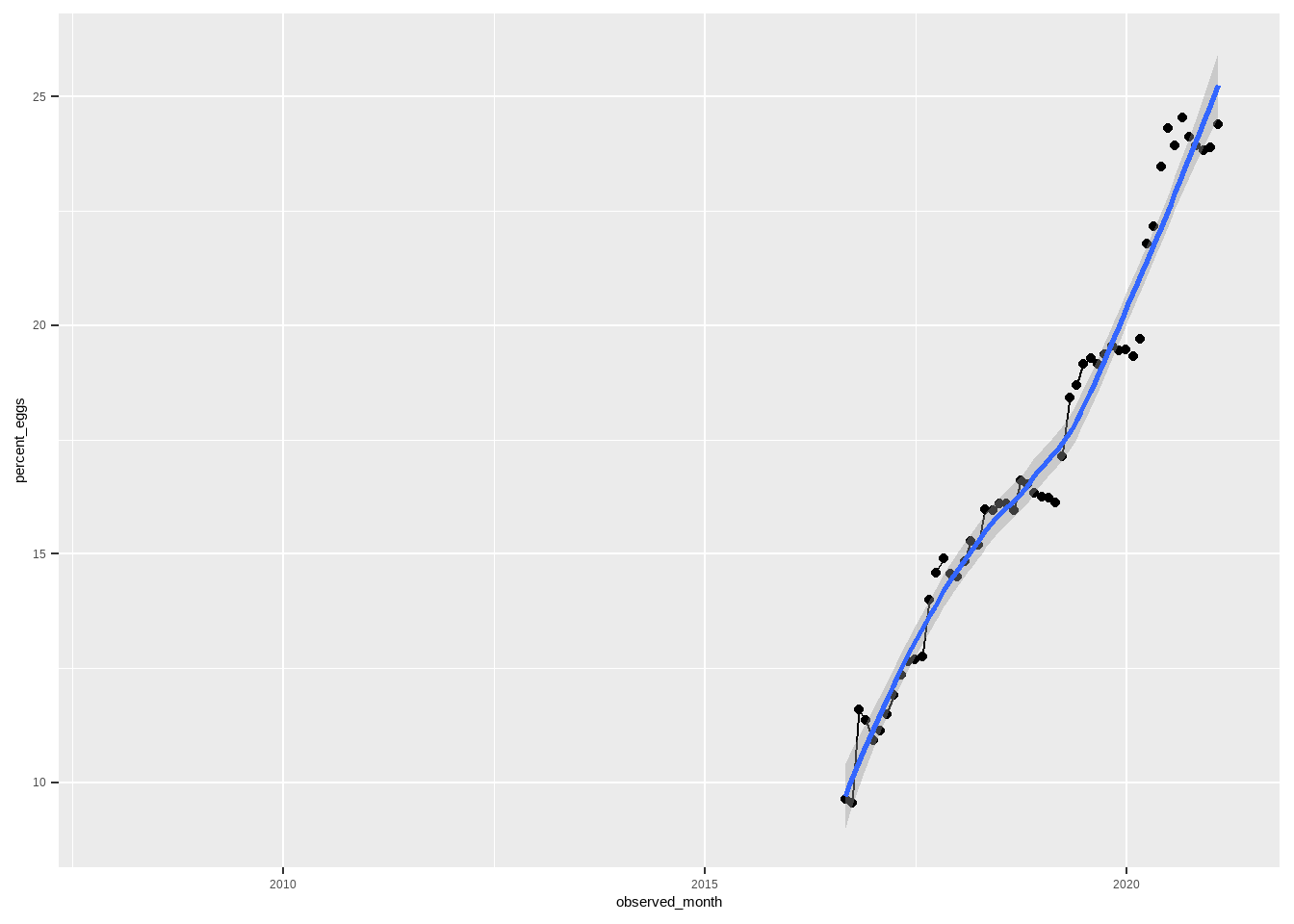
Change in Percentage of Cage-Free Hens/Eggs Over Time
It appears that the percentage of cage-free eggs has increased dramatically over time.
Machine Learning
At this point, I would like to see machine learning models for linear regression, tree, random forest, and LASSO to predict egg count and compare its performance on “training” data to “test” data.
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 89508484.
# RMSE for Testing Data: 89508484
It is slightly surprising to me that the LASSO model performs better on the testing data than on the training data.
Discussion
From this analysis, the hypothesis that August is the month of highest egg production has been proved false. However, the hypothesis that percentage of cage-free hens and eggs increasing over time appears to be confirmed. While none of the models fitted to the training data had a low RMSE, the LASSO model had the lowest of them and performed better on the testing data than on the training data.