# Set Variable for Where Original Data is Locateddata_location <-here("fluanalysis", "data", "cleaned_data.rds")# Read in Original Dataoriginal_data <-readRDS(data_location)
Data Splitting
# Set Seed for Reproducible Analysisset.seed(2023)# Split Original Data into Training and Testing Datadata_split <-initial_split(original_data, prop =3/4)# Create Data Frames from Split Datatrain_data <-training(data_split)test_data <-testing(data_split)
Workflow Creation and Model Fitting
Create Recipe for Fitting Logistic Model (Categorical Outcome)
flu_recipe <-recipe(Nausea ~ ., data = train_data)
Workflow to Create Logistic Model
# Set Model to Logistic Regressionlogistic_regression_model <-logistic_reg() %>%set_engine("glm")# Specifying Workflowlogistic_workflow <-workflow() %>%add_model(logistic_regression_model) %>%add_recipe(flu_recipe)# Fitting/Traininglogistic_fit <- logistic_workflow %>%fit(data = train_data)
Model 1 Evaluation
Prediction + ROC Curve
# Training Datapredict(logistic_fit, train_data)
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
# A tibble: 547 × 1
.pred_class
<fct>
1 No
2 No
3 No
4 No
5 No
6 No
7 No
8 No
9 Yes
10 No
# … with 537 more rows
train_augment <-augment(logistic_fit, train_data)
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
# A tibble: 183 × 1
.pred_class
<fct>
1 Yes
2 No
3 No
4 Yes
5 No
6 Yes
7 No
8 Yes
9 No
10 No
# … with 173 more rows
test_augment <-augment(logistic_fit, test_data)
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
prediction from a rank-deficient fit may be misleading
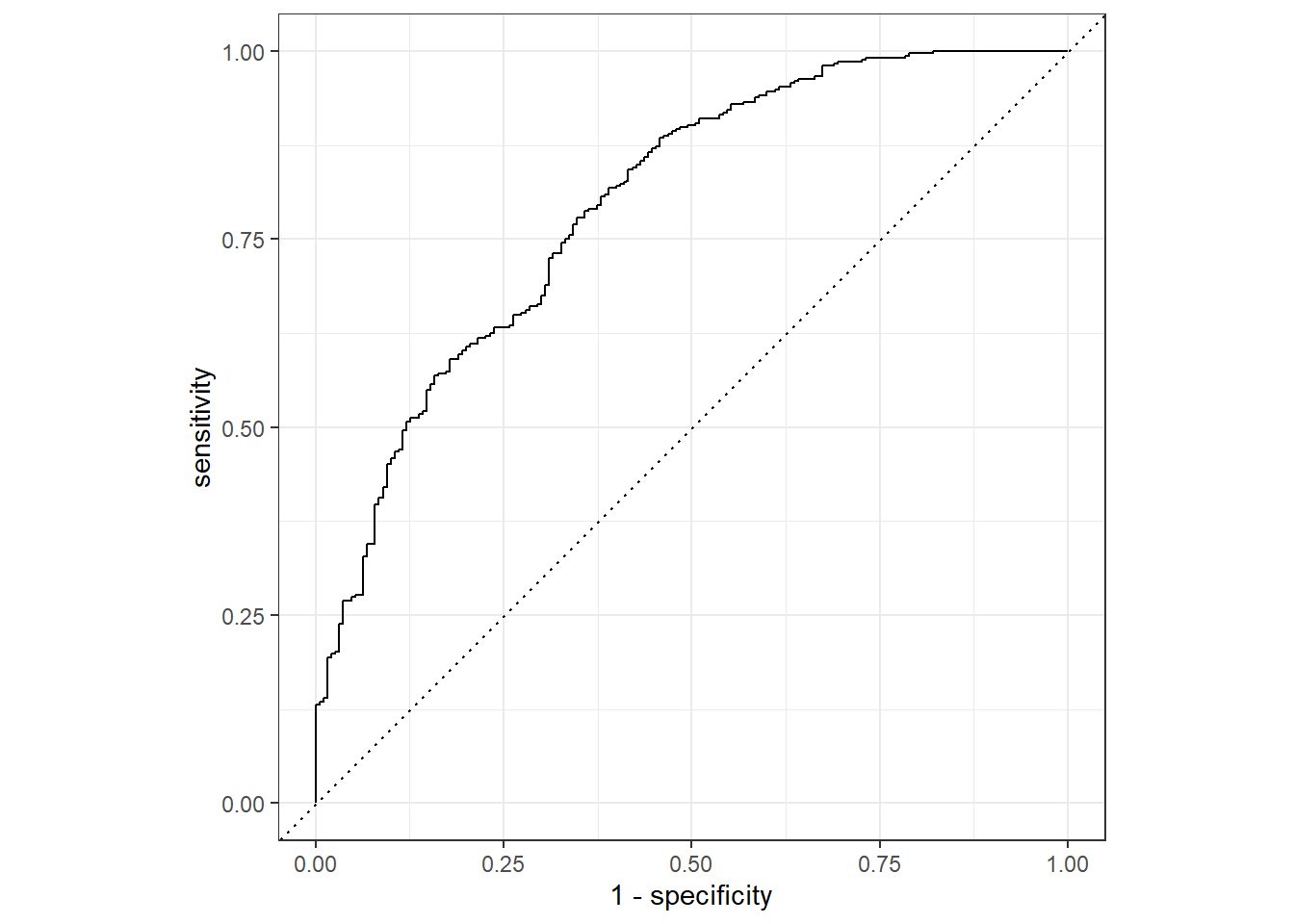
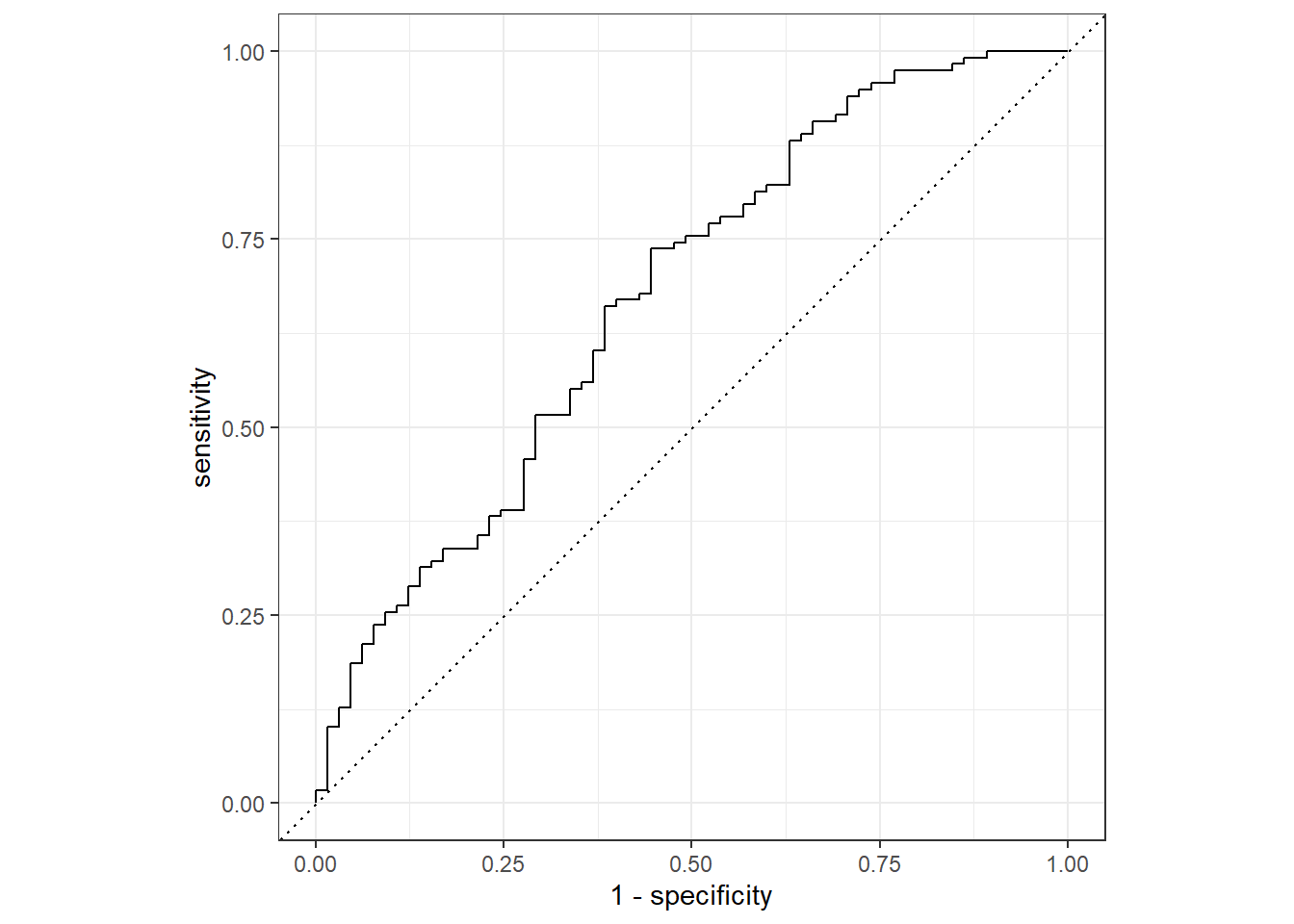
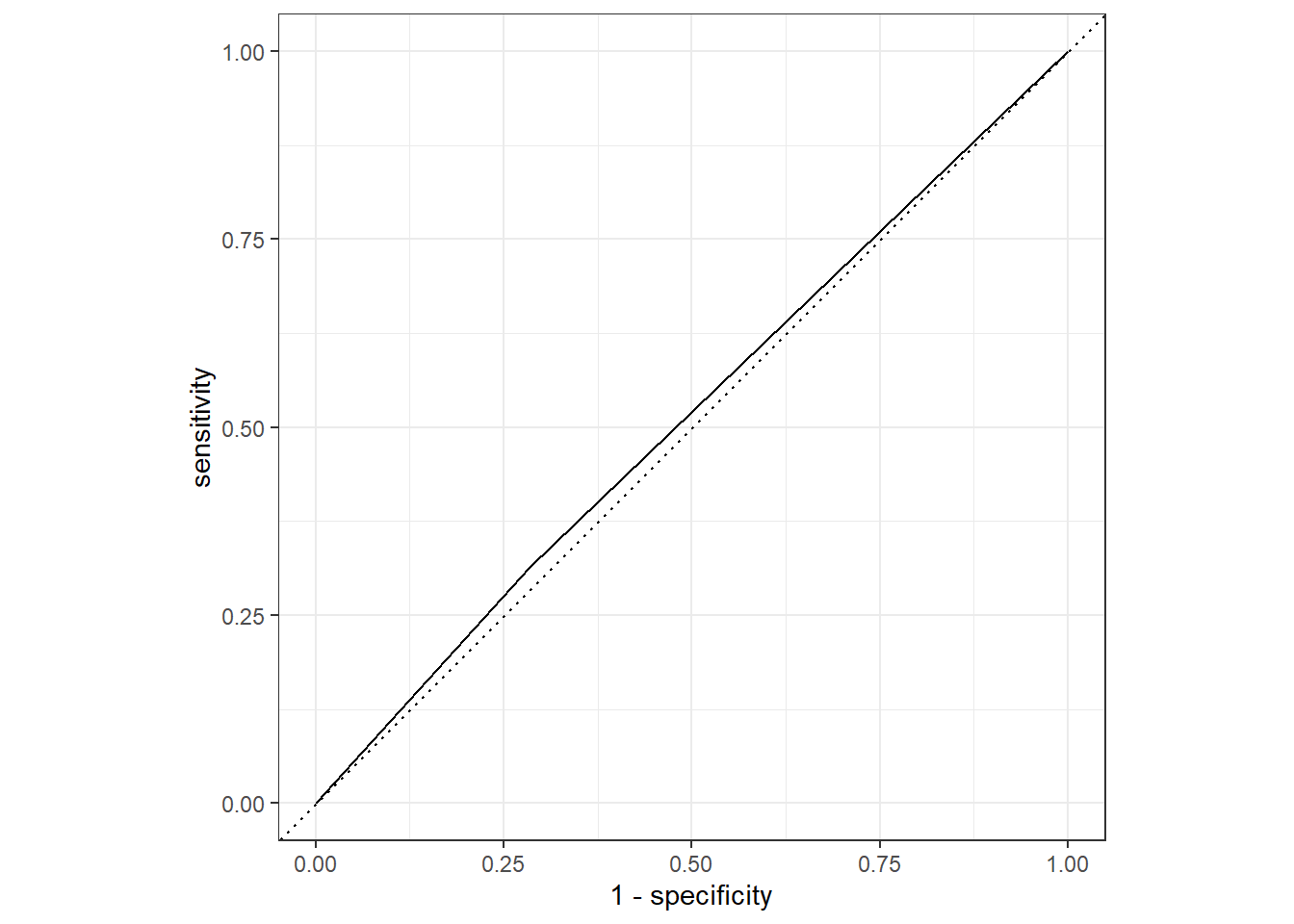
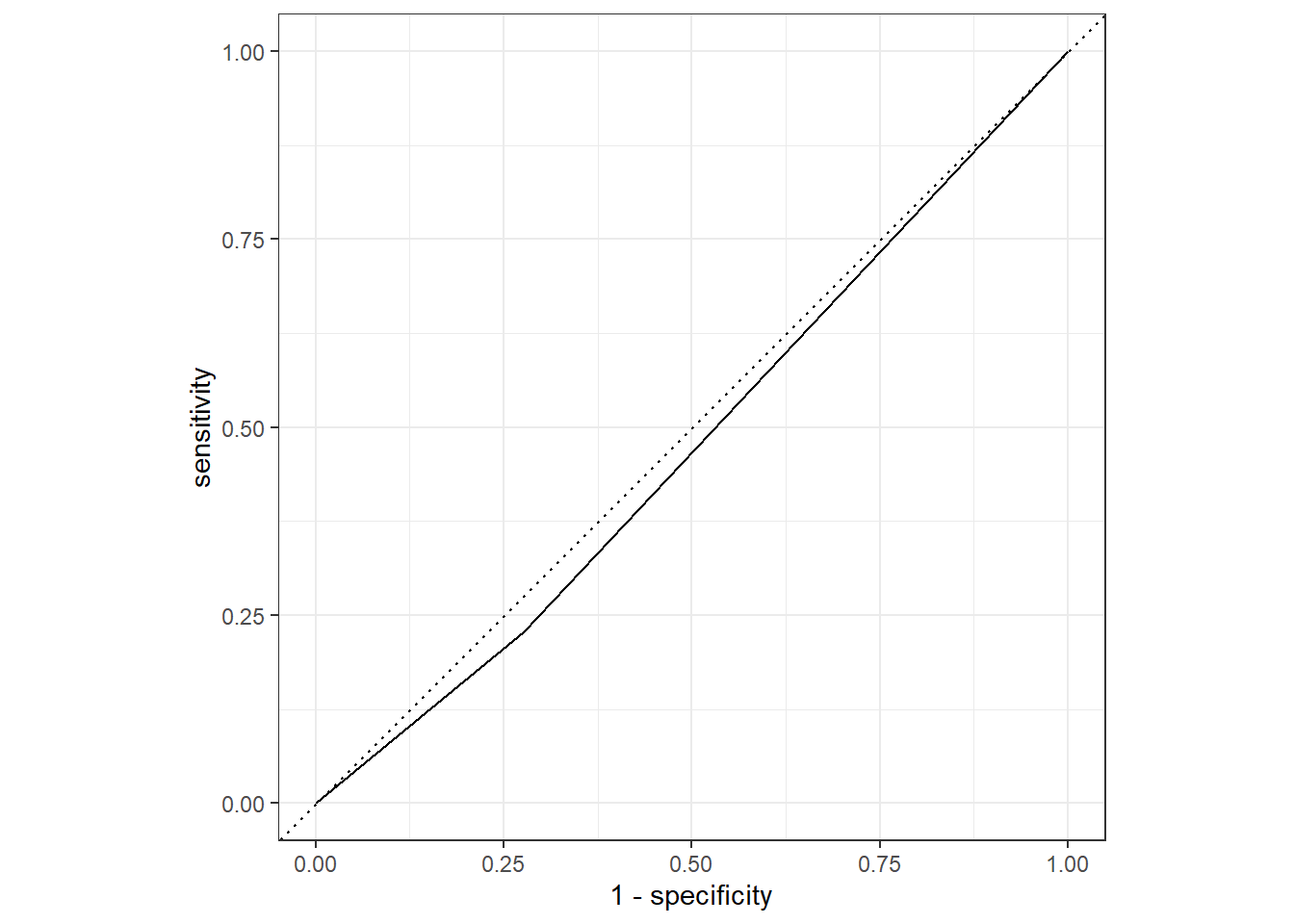
The alternative model that uses just one predictor appears to be much worse (Training ROC-AUC: 0.515, Test ROC-AUC: 0.476) than the model that uses all predictors (Training ROC-AUC: 0.796, Test ROC-AUC: 0.672).
This section added by CONNOR H ROSS (below)
Part II: Continous Outcome
# Part II: Continous Outcome## Libraries already loaded above (Thanks Kailin :))## Set seed for reproducibilityset.seed(2)## Split 3/4 of the data into the training setflu_splitc1 <-initial_split(original_data, prop =3/4)## Create data frame for the two sets:train_datac1 <-training(flu_splitc1)test_datac1 <-testing(flu_splitc1)## Full model### Creating my recipeflu_recipec1 <-recipe(BodyTemp ~ ., data = original_data)### Prepare modellin_modc1 <-linear_reg() %>%set_engine("lm")### Create workflowflu_wflowc1 <-workflow() %>%add_model(lin_modc1) %>%add_recipe(flu_recipec1)### Prepare the recipe and train the modelflu_fitc1 <- flu_wflowc1 %>%fit(data = train_datac1)### Tidy outputflu_fitc1 %>%extract_fit_parsnip() %>%tidy()
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 1.15
### One Predictor## Creating my recipe2flu_recipec2 <-recipe(BodyTemp ~ RunnyNose, data = original_data)#### Previous model will work### Create workflow2flu_wflowc2 <-workflow() %>%add_model(lin_modc1) %>%add_recipe(flu_recipec2)### Prepare the recipe and train the model2flu_fitc2 <- flu_wflowc2 %>%fit(data = train_datac1)### Tidy output2flu_fitc2 %>%extract_fit_parsnip() %>%tidy()